Agent performance was never the hard part
As a Principal Engineer at Faculty, I spent a year building an agent harness for large enterprises in regulated domains. Our goal was production-level performance. Details are anonymised.
Agent performance was never the hard part. Persisting and linking their outputs, decomposing them along organisation lines, making them resilient to the real world, and pushing performance through the human-accuracy ceiling are the hardest parts.
Our setup
We used a lightweight, domain-agnostic data model: every agent emits steps: a record of actions it actually took (e.g., “read the document”, “emailed the broker”). A run is a single invocation: an ordered set of steps where success is asserted by the agent, not inferred by the harness (“email server was down, run failed”). A task represents the business outcome such as “insurance quote complete” and it owns many runs. The run history is effectively a long-horizon resume for the task; an insurance quote that takes three weeks of broker correspondence is one task and N runs, each picking the workflow up with new information rather than resuming a paused process.
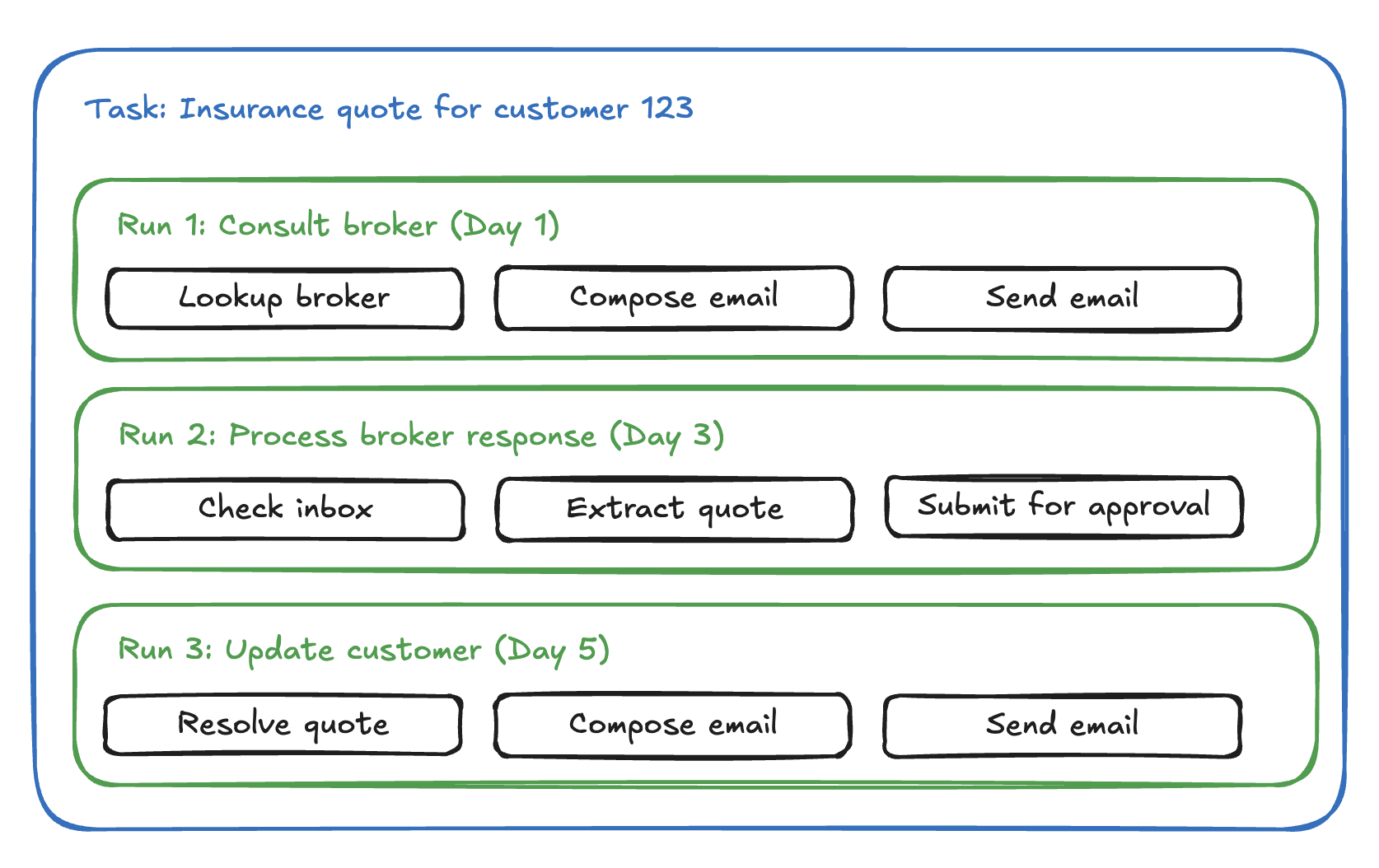
The harness holds no domain knowledge: “get a quote by doing X” never enters it. We built customisation around three consumers: a builder with the domain knowledge who writes the agent, a dashboard user who turns its outputs into business value, and a manager who owns the production bar. The harness connects them using the task/run/step model. Customisation is convention-based discovery.
We prioritised first-class support for eval-driven development. The production bar in a regulated domain is near-human accuracy with audit-grade reliability, so roughly 75% of the engineering went into quantifying agent performance rather than building agents. When running evaluations is low-friction, implementing agent improvements is intuitive and easy.
Observation 1: Agent design is org design
A valuable business decision is rarely one agent’s output. “Offer this insurance quote” requires lots of complex inputs: N teams each own a sub-determination, and the decision exists only once their results compose. Each team has the domain knowledge to build its own agent; none of them should need to understand the others’ to ship. Friction maps onto team boundaries. Conway’s Law in action: the system was going to mirror the organisation whether we designed for it or not. The choice was whether that mirroring was explicit and safe, or implicit and a source of coupling.
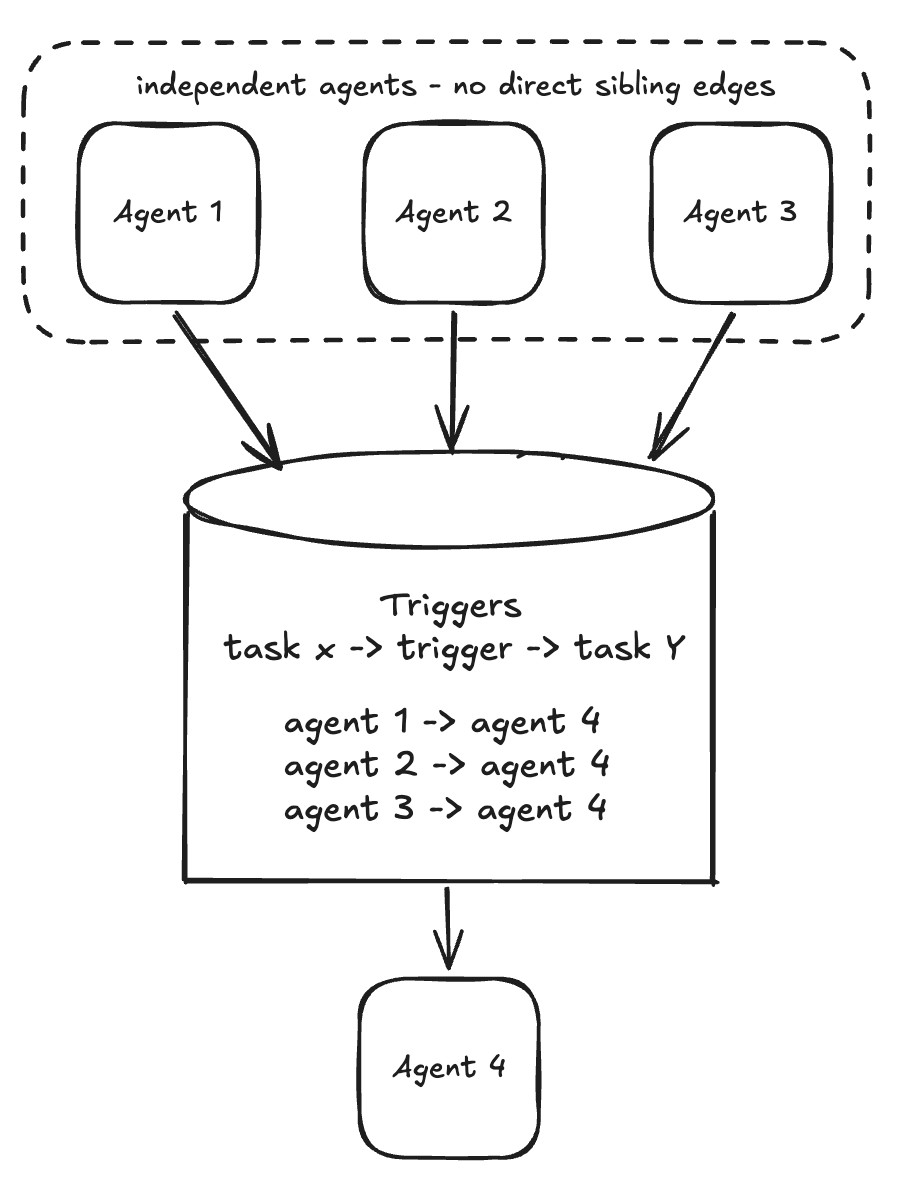
We made it explicit by modelling the dependency structure as what it already is: a DAG. Each agent is a node, each cross-team dependency is an edge. The organisation’s decision graph and the agent graph are the same graph.
On a successful run the harness derives a trigger event from the output and records it. A downstream agent subscribes to the triggers it depends on; when one fires, it hydrates its state from the upstream task in the shared model and proceeds. No message bus, no new orchestration tier: the edge is a row in the trigger collection. To keep the harness’s infrastructure footprint light, trigger state lives as one collection in an existing database: a lookup table, task X → trigger → task Y.
Two properties fall out of this structure rather than being built on top of it.
The first is provenance. Because every edge is a recorded task → trigger → task row, the causal chain behind any output is queryable. In a regulated domain that is not a convenience: “why did the agent do this” has to be answerable, and the trigger table makes the answer a queryable artefact instead of something reconstructed from logs after the fact.
The second is failure isolation. A trigger is emitted only on successful completion, so a failed upstream run simply produces no edge. Downstream agents don’t receive a corrupt input to defend against; they receive nothing, and don’t run. Cascading failure is prevented by the absence of the trigger: upstream success is a structural precondition of the edge. We can still query the negative space to answer questions like “why didn’t the agent run”.
A team could build, evaluate, and ship its agent against a single contract: emit a trigger on success, subscribe to the triggers you depend on. There is no synchronous coordination with any other team. The coordination problem was moved into a primitive small enough that nobody had to negotiate it.
Our leverage came from providing a harness that let builders stop fighting their organisational shape.
Observation 2: The world is unreliable, so the agent must be retryable
The internal APIs these agents had to call were built to serve humans through dashboards, not machines through automation. They were rarely set up for machine-to-machine auth, and they were sized for human throughput. An agent clears in minutes a queue of alerts a team would have worked through over a day. Under that profile the APIs we depended on degraded or failed. The agent had to be built to operate in that world.
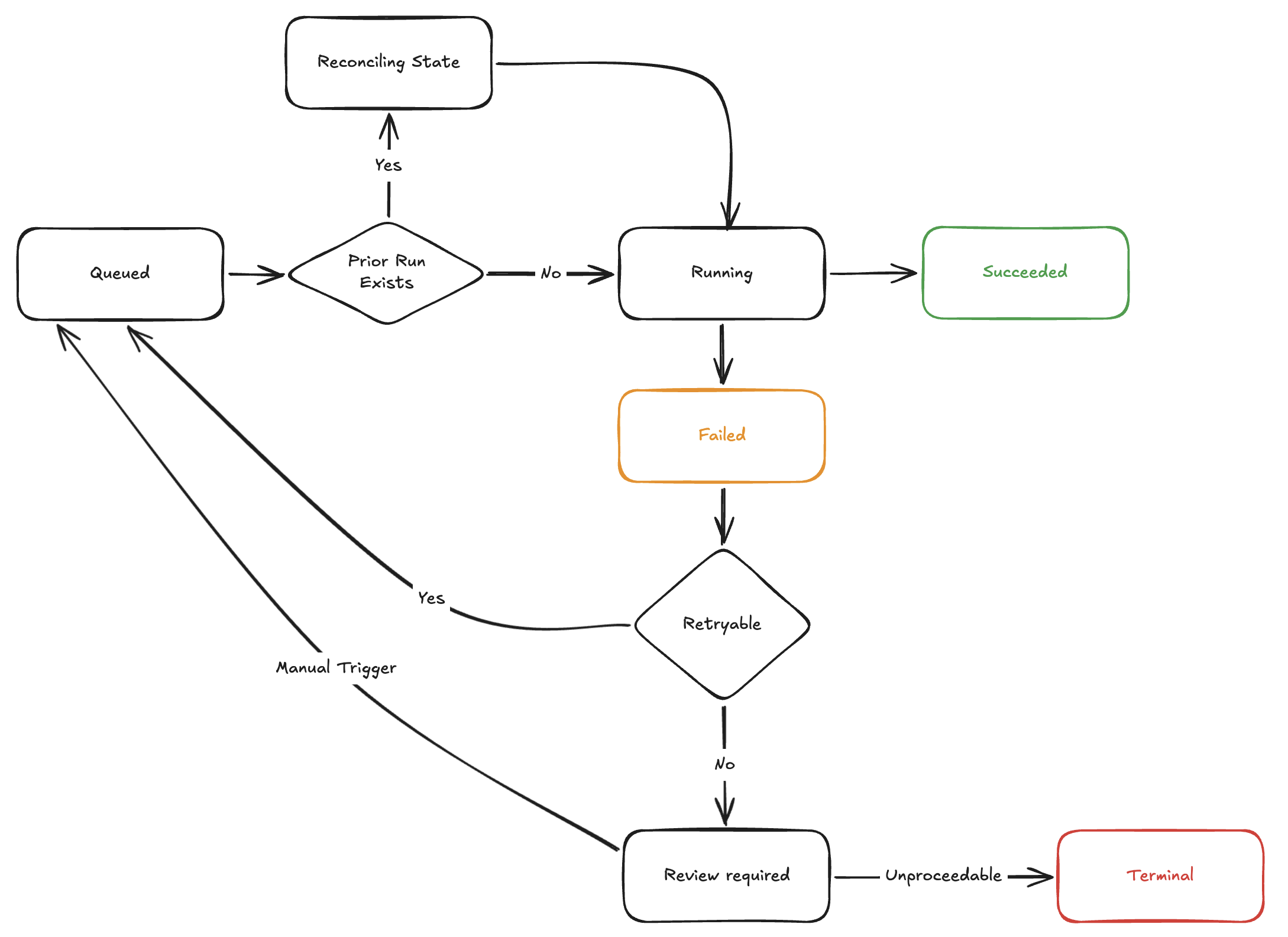
We modelled agents as retryable at the run level: a run either succeeds or fails, any failure is classified as retryable or terminal, and retryable failures are re-enqueued. A variant of durable execution (Temporal, Azure Durable Functions).
Side effects from failed runs are still real and irreversible: an email was sent, a broker was contacted. Our retries compute what already happened in the world and resume past it: task-level idempotency of run-level concepts. The logic that defines “what already happened” is domain reasoning and is performed by the agent. The harness presents the raw information to enable that reconciliation. Requiring agent builders to write the reconciliation logic was a cost we accepted, because an agent that cannot be safely retried cannot run at scale in production.
In exchange for the builder burden, the contract abstracts cleanly over different orchestration providers. Where a provider supported mid-flight resume, the reconciliation step handed control back into the run in place; where it did not, the same idempotency contract made a restart-from-top safe. We supplemented the automatic retry flow with an operator dashboard trigger: a deliberate human override that leant on additional human context to get failed runs to completion.
Observation 3: The world’s answer is a function of when you ask
In fraud and insurance the label is right-censored. At decision time you observe that a confirming event has not happened yet: “the user has not completed ID verification” is not the same as it never happening; the true label matures as those events resolve, so a decision recorded early sits on a less mature label than the same decision recorded later. Response = f(query, t), not f(query).
A human team worked a queue over a day, and that lag was time in which labels quietly matured before each decision was recorded. An agent clears the same queue in minutes, moving every decision earlier in label-time. The agent is not less accurate; the evaluation is now scoring early-time decisions against a reference set whose labels were observed later and more matured.
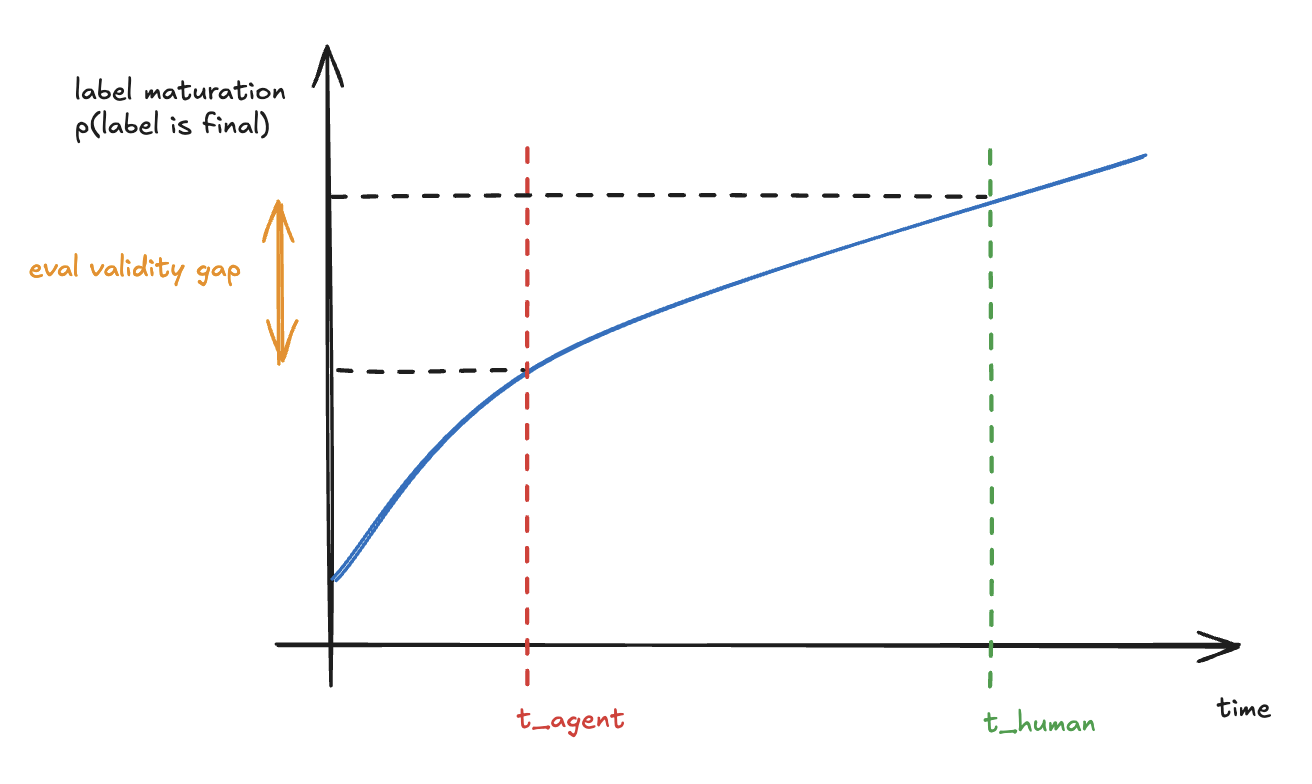
The textbook fix is an as-of filter that reproduces the world at T. Most internal APIs have no notion of T; where one existed it was not built for the concurrency of thousands of eval runs. The same hostile infrastructure from Observation 2, in the time dimension. It set the ceiling on evaluation throughput: the full set could rarely complete overnight, so it ran periodically while a label-balanced subset weighted toward stubborn failures ran daily.
Snapshotting to make evaluation reproducible was structurally impossible: the human’s original decision used data fetched through the human’s tooling, never under the harness’s instrumentation.
So we experimented with instrumenting the agent’s world instead. Every HTTP response the agent received could be hashed and stored, and runs were front-loaded so a disagreement could trigger a re-run against fresh labels. The harness could then flag when the backing API’s answer had substantively changed between calls. That reframes the disagreement: was the agent wrong, or did the world move?
We could now evaluate fairly against a world that both failed and moved. What we could not do was close the gap to human accuracy.
Observation 4: The ceiling is human, and autonomy has to be earned
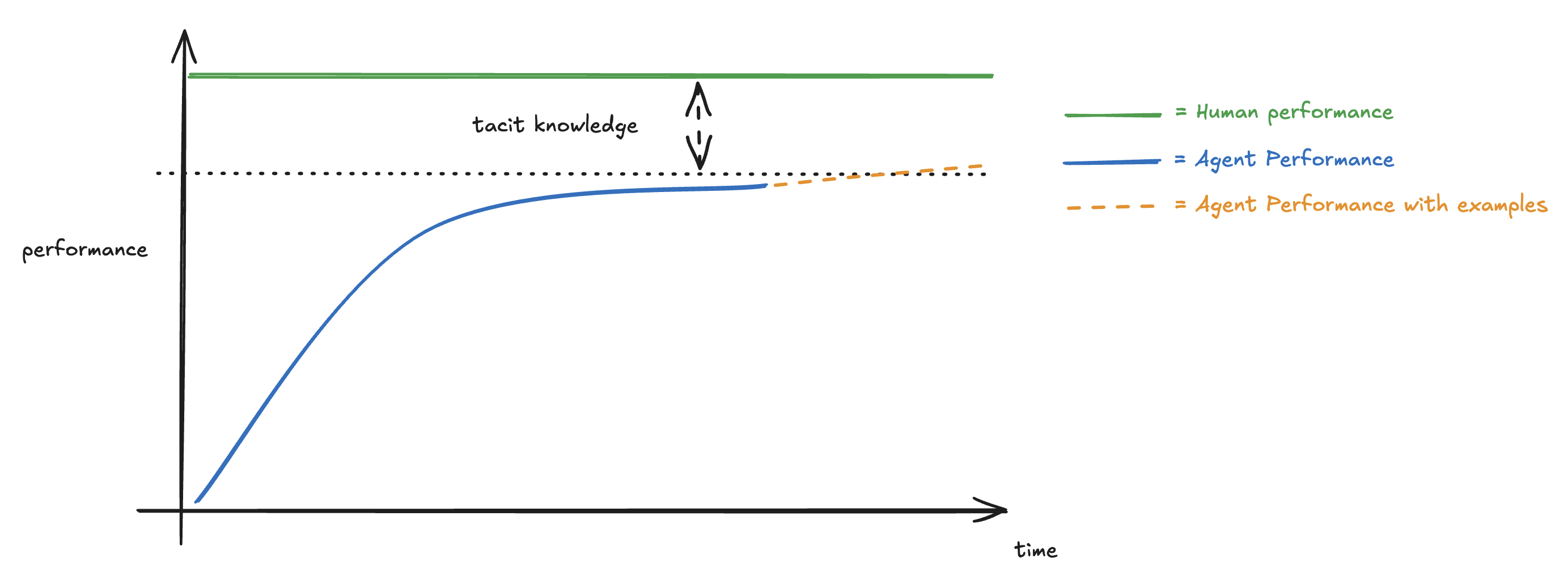
The last gap to human accuracy was not environmental. On many tasks agent performance was asymptotic to human accuracy and recall. The residual was tacit knowledge: the judgement an experienced person accrues doing the role. There was only so much explicit information to give; past that, the curve flattened.
We tried to replicate the human learning curve by injecting salient examples at inference time. It produced an uplift only when the retrieved examples were highly relevant. Below that bar it did harm: under the ambiguity inherent in these tasks the model leaned on the examples, so a marginally-relevant neighbour did not merely fail to help, it introduced regressions. The relevance bar was therefore high, and the binding constraint was supply. From exploration, a usefully close neighbour existed for 2% of validation-set runs.
The way to raise the % with near neighbours is density: more examples, closer neighbours, a shorter distance to a useful one. Once the agent was live, every confirmed failure required two pieces of feedback in the rollout review flow: correct/incorrect/partial, and a free-text reason. That feedback fed the dynamic example store directly. Each confirmed failure shortened the expected distance to the nearest useful neighbour for the cases most like it.
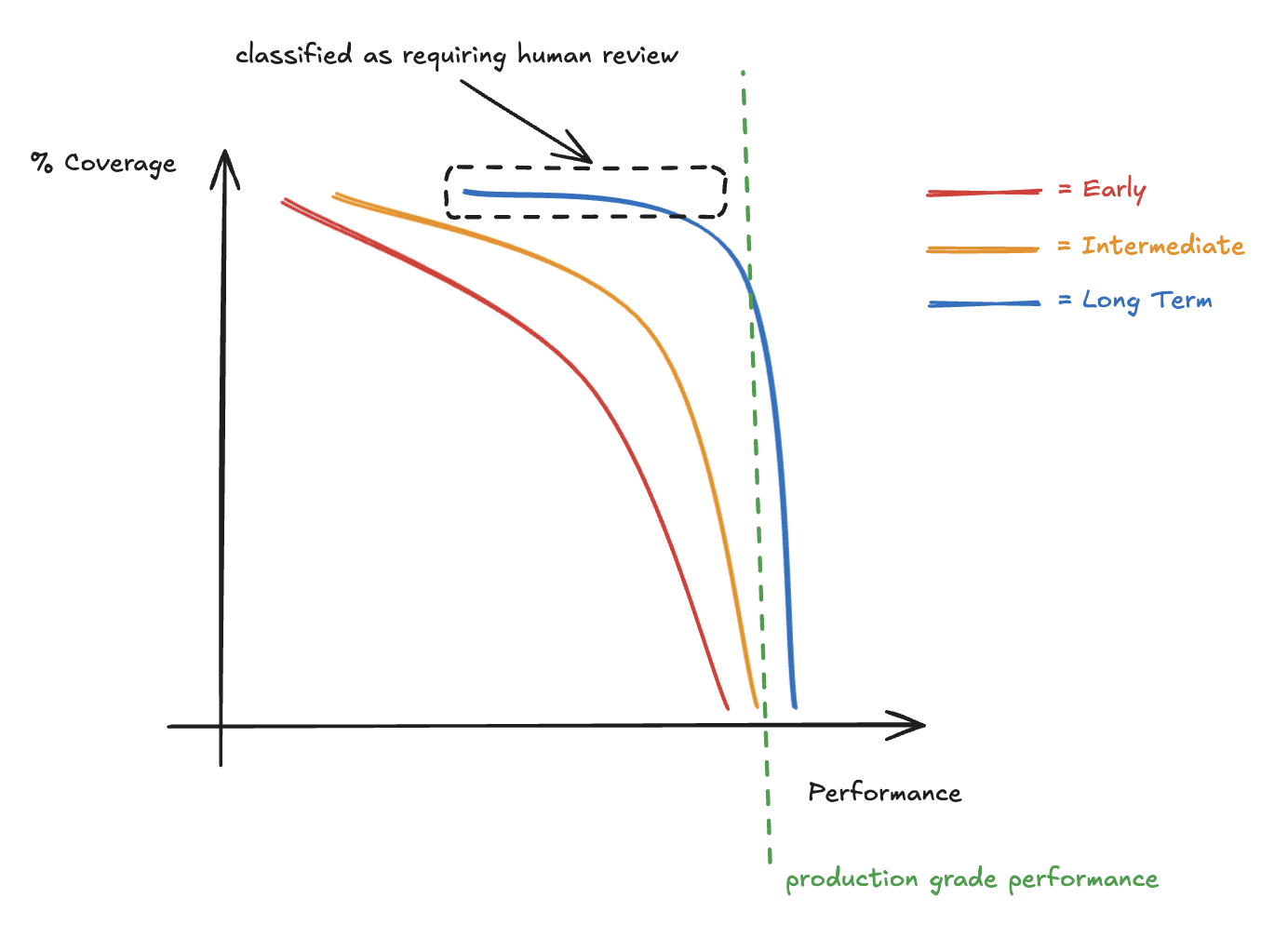
Density helps slowly, and some cases have no near neighbour at all. Where the agent could not make a reliable determination, we did not force autonomy. We used a cheap triage model (LightGBM) to identify the hardest cases and route them directly to human review. Architecturally, this additional functionality was modelled as post-processing nodes downstream of the domain agent but inside the same run and task as far as the dashboard user was concerned.
The agent runs wrapped in higher-order nodes that enforce the production bar, and the domain expert who built the agent is decoupled from being personally on the hook for the task succeeding / aggregate performance. The bar itself is owned by the manager: the production threshold is theirs and the wrapping is how that threshold is enforced.
The agent was the tractable component
Everything difficult lived in the world and the organisation around it. The part that’s still hard, accruing experience, is a real boundary the harness narrows but does not erase.